Erakondade valimisprogrammid on oma lubaduste mitmekesisuses ja paljususes tervikuna hoomamatud. Nendest üldise pildi saamisel võib meile abiks olla kvantitatiivne tekstianalüüs, mis on võimeline korraga analüüsima suurt hulka tekste ning nendest tuvastama seoseid, mida palja silmaga ei ole võimalik märgata. Siinkohal on vaatluse alla on võetud järgnevate erakondade valimisprogrammid 2019. aasta Riigikogu valimistel:
- Eesti 200
- EKRE
- Elurikkuse Erakond
- Isamaa
- Keskerakond
- Reformierakond
- Rohelised
- Sotsid
- Vabaerakond
Iga erakonna valimisprogramm on vastavalt oma enda struktuurile jaotatud alajaotusteks (millest on eemaldatud viited erakonna enda nimele) ning niimoodi on analüüsitud kokku 299 erinevat “dokumenti”. Tekstide analüüsiks ettevalmistamiseks on kasutatud eesti keele töötlemiseks loodud tarkvara estnltk 1.4.1 (vaata siit). Tekstides sisalduvad sõnad on lemmatiseeritud (st. viidud algvormidesse) ning eemaldatud on kirjavahemärgid ja stoppsõnad (peamiselt sidesõnad, mis ei väljenda tähendust).
Valimisprogrammide analüüsimiseks on kasutatud meetodit nimega teemade modelleerimine (vaata siit), mis on võimeline tuvastama tekstides koos esinevaid sõnade kogumikke, st. üksteisega samas kontekstis seotud sõnu, mis moodustavad ühe teema. Samuti on selle meetodi abil võimalik antud konteksits modelleerida teemade osakaalu ühes või teises dokumendis vastavalt sellele, millise erakonna programmist tekstilõik on pärit. Analüüsist on välja jäetud sellised sõnad, mis esinesid vähem kui üheksas programmilõigus ning seega oli analüüsi kaasatud kokku 1179 erinevat sõna 299 dokumendi lõikes. Strukturaalsel teemade modelleerimise mudelil paluti niimoodi eristada tekstidest 9 teemat. Teemade arv on ainus suurus, mis tuleb mudelile ette anda ning siinkohal sai valitud 9, kuna nii joonistusid välja selgesti eristatavad teemad, millest praktiliselt kõiki oli võimalik sisuliselt tõlgendada. Väiksema ette antud teemade arvuga sulanduvad need teemad kokku ning suurema arvuga tuvastab algoritm üha enam teemasid, mida ei ole võimalik sisuliselt tõlgendada.
Need 9 eristuvat teemat olid järgnevad (vajuta pildil, et näha suuremalt):

Iga teema koosneb sõnadest, mille puhul algoritm tuvastas, et nad tõenäolisemalt kipuvad koos esinema teatud valimisprogrammide osades aga mitte teistes. Need sõnapilved seega kujutavad endast üksteisega seotud sõnade kogumikke ehk teemasid. Pealkirjad, mis teemadele antud, on selles mõttes arbitraasred, et nad on vaataja tõlgendus neid sõnu kokku siduvast sisust. Kui inimese asemel peaks valimisprogramme lugema arvuti ning kui temalt küsida, et mis on praeguste Riigikogu valimiste 9 põhiteemat, siis oleksid need just sellised teemad.
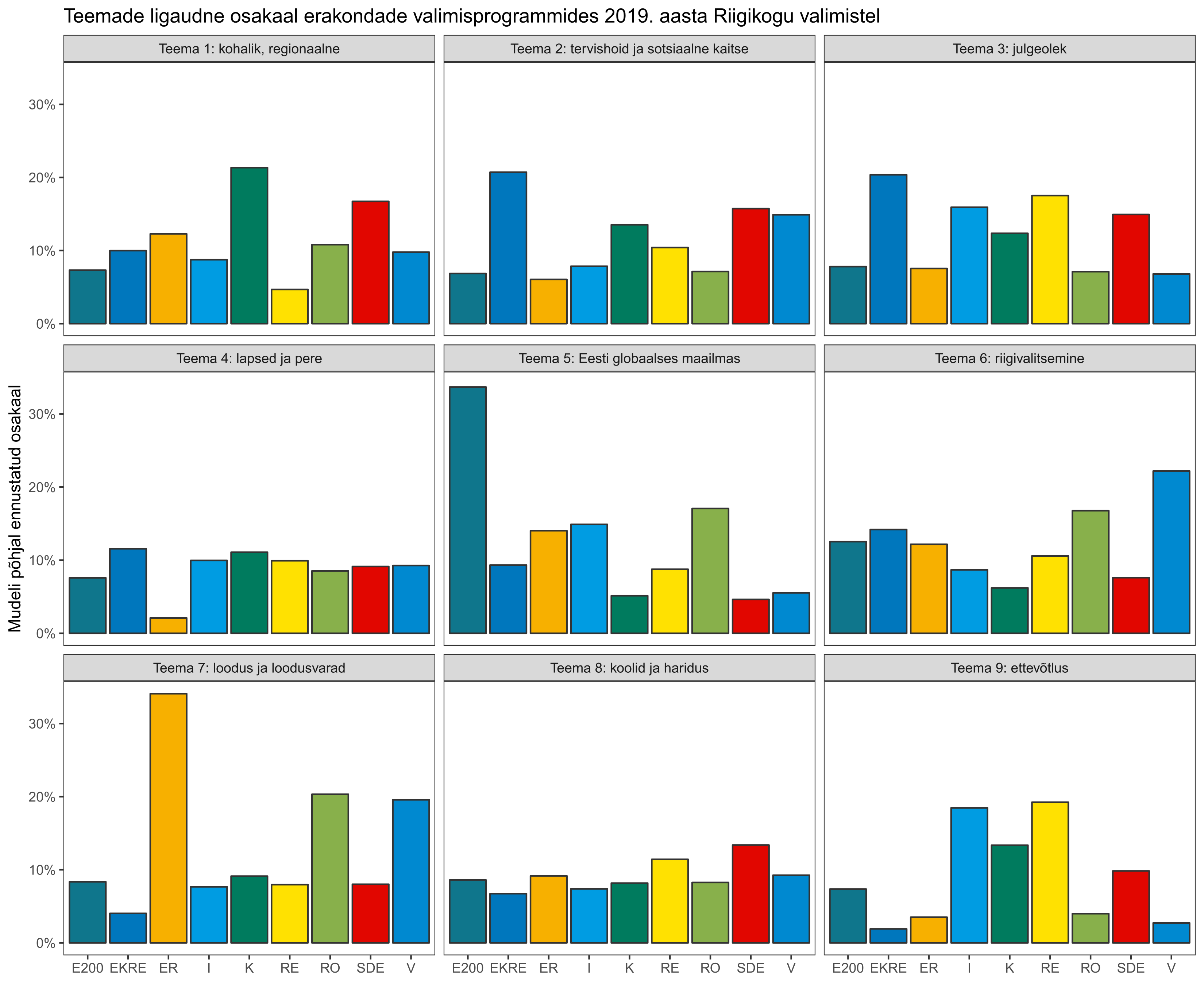
Iga valimisprogrammi osa on modelleeritud kui segu vastavatest teemadest ning iga teema osakaalu ühes dokumendis on ennustatud vastavalt sellele, millisele erakonnale üks või teine programmilõik kuulus. Nii on võimalik tuvastata, kas mõni erakond on mõne kindla teemaga seotud või kas näiteks on teemasid, mis on leidnud samaväärset kajastust kõikide erakondade programmides. Kuna analüüsitud tekstilõike on statistilises mõttes siiski üpriski vähe, on taolised seosed erakondadega vägagi tinglikud ning neid tasub võtta teatud mõistliku skepsisega. Kuid üldisi tendentse ja suundi nad siiski näitavad. Iga teema seos erakondadega on välja toodud järgneval joonisel (vajuta pildil, et näha suuremalt).
Tekstianalüüsi ja masinõppe meetodeid on võimalik kasutada ka valimisprogrammide sõnavara ja sellega seotud tähenduste erinevuste analüüsimiseks. Word2vec (vaata siit) on masinõppe mudel, mida on võimalik rakendada tohtu suurtel tekstihulkadel analüüsimaks seda, millises kontekstis, st. koos milliste teiste sõnadega, ühte või teist sõna kasutatakse. Nii on võimalik hinnata, kui erinevad on sõnad oma kasutuskonteksti poolest ning seeläbi kui sarnase või erineva tähendusega nad on. Eesti keele põhjal treenitud vastavad mudelid on kättesaadavad siit.
Esmajoones on neid võimalik kasutada sõnade omavahelise erinevuse hindamiseks, kuid selle põhjal on üles ehitatud ka metoodikad tekstide kui tervikute erinevuste hindamiseks. Antud juhul on valimisprogrammide üldiste erinevuste hindamiseks kasutatud metoodikat, mis eesti keeles võiks olla “sõnade liigutamise kaugus” (inglise keeles word mover’s distance, ülevaate saamiseks vaata siit). Taoline kaugusemõõdik hindab seda, kui palju on ühe teksti sõnu vaja “liigutada” eelnevalt treenitud Word2vec mudeli statistilises ruumis selleks, et jõuda ühest tekstist teise tekstini. Niimoodi saadud kauguse arvuline väärtus ei ole otseselt tõlgendatav ning see annab meile aimu üksnes sellest, kui sarnasemad või erinevamad on erakondade programmid üksteisest. Kahe identse teksti omavaheline kaugus vastavalt sellele mõõdikule on 0. Järgnev tabel toob välja kõikide erakondade paariskaupa kaugused üksteisest vastavalt sellele meetodile.
| E200 | EKRE | Sotsid | Isamaa | Reform | Vaba | Kesk | Rohelised | Elurikkuse | |
| E200 | 2.39 | 1.68 | 1.64 | 1.61 | 1.73 | 1.71 | 1.71 | 2.16 | |
| EKRE | 2.28 | 2.35 | 2.45 | 2.41 | 2.34 | 2.51 | 2.69 | ||
| Sotsid | 1.57 | 1.54 | 1.6 | 1.46 | 1.74 | 2.19 | |||
| Isamaa | 1.42 | 1.69 | 1.53 | 1.77 | 2.15 | ||||
| Reform | 1.67 | 1.53 | 1.81 | 2.12 | |||||
| Vaba | 1.68 | 1.68 | 2.07 | ||||||
| Kesk | 1.78 | 2.12 | |||||||
| Rohelised | 2.09 | ||||||||
| Elurikkuse |
Tinglikult on taolisi kaugusi võimalik esitada ka kahemõõtmelisel tasapinnal, kuigi sellisel juhul läheb mingi osa välja toodud tabelis sisalduvast informatsioonist kaduma. Madalamamõõtmelisema representatsiooni loomiseks on kasutatud mitmedimensioonilist skaleerimist (MDS, vaata siit) eeldades, et tabelis väljendatud kaugused on mõõdetud suhteskaalal (ratio scale). Sellise MDS mudeli kokkusobivus algsete paariskaupa kaugustega on madal (Stress-1 väärtus on 0.265), kuid teatud tähendusliku, mis sest, et lihtsustatud, pildi annab see siiski. Seega, kahemõõtmelises ruumis oleksid need kaugused järgnevad.
